When it comes to machine learning tasks such as nomenclature or regression, propinquity techniques play a key role in learning from the data. Many machine learning methods injudicious a function
10.2k
By Nick Cotes
When it comes to machine learning tasks such as nomenclature or regression, propinquity techniques play a key role in learning from the data. Many machine learning methods injudicious a function or a mapping between the inputs and outputs via a learning algorithm.
In this tutorial, you will discover what is propinquity and its importance in machine learning and pattern recognition.
After completing this tutorial, you will know:
What is approximation
Importance of propinquity in machine learning
Let’s get started.
A Gentle Introduction To Approximation. Photo by M Mani, some rights reserved.
Tutorial Overview
This tutorial is divided into 3 parts; they are:
What is approximation?
Approximation when the form of function is not known
Approximation when the form of function is known
What Is Approximation?
We come wideness propinquity very often. For example, the irrational number ? can be approximated by the number 3.14. A increasingly well-judged value is 3.141593, which remains an approximation. You can similarly injudicious the values of all irrational numbers like sqrt(3), sqrt(7), etc.
Approximation is used whenever a numerical value, a model, a structure or a function is either unknown or difficult to compute. In this vendible we’ll focus on function propinquity and describe its using to machine learning problems. There are two variegated cases:
The function is known but it is difficult or numerically expensive to compute its word-for-word value. In this specimen propinquity methods are used to find values, which are tropical to the function’s very values.
The function itself is unknown and hence a model or learning algorithm is used to closely find a function that can produce outputs tropical to the unknown function’s outputs.
Approximation When Form of Function is Known
If the form of a function is known, then a well known method in calculus and mathematics is propinquity via Taylor series. The Taylor series of a function is the sum of infinite terms, which are computed using function’s derivatives. The Taylor series expansion of a function is discussed in this tutorial.
Another well known method for propinquity in calculus and mathematics is Newton’s method. It can be used to injudicious the roots of polynomials, hence making it a useful technique for approximating quantities such as the square root of variegated values or the reciprocal of variegated numbers, etc.
Approximation When Form of Function is Unknown
In data science and machine learning, it is unsupportable that there is an underlying function that holds the key to the relationship between the inputs and outputs. The form of this function is unknown. Here, we discuss several machine learning problems that employ approximation.
Approximation in Regression
Regression involves the prediction of an output variable when given a set of inputs. In regression, the function that truly maps the input variables to outputs is not known. It is unsupportable that some linear or non-linear regression model can injudicious the mapping of inputs to outputs.
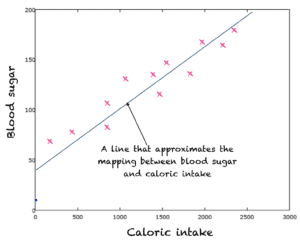
For example, we may have data related to consumed calories per day and the respective thoroughbred sugar. To describe the relationship between the calorie input and thoroughbred sugar output, we can seem a straight line relationship/mapping function. The straight line is therefore the propinquity of the mapping of inputs to outputs. A learning method such as the method of least squares is used to find this line.
A straight line propinquity to relationship between caloric count and thoroughbred sugar
Approximation in Classification
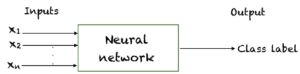
A xerox example of models that injudicious functions in nomenclature problems is that of neural networks. It is unsupportable that the neural network as a whole can injudicious a true function that maps the inputs to the matriculation labels. Gradient descent or some other learning algorithm is then used to learn that function propinquity by adjusting the weights of the neural network.
A neural network approximates an underlying function that maps inputs to outputs
Approximation in Unsupervised Learning
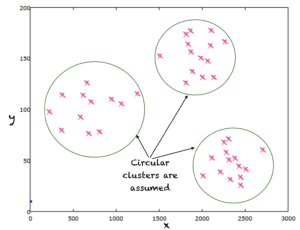
Below is a typical example of unsupervised learning. Here we have points in 2D space and the label of none of these points is given. A clustering algorithm often assumes a model equal to which a point can be prescribed to a matriculation or label. For example, k-means learns the labels of data by thesping that data clusters are circular, and hence, assigns the same label or matriculation to points lying in the same whirligig or an n-sphere in specimen of multi-dimensional data. In the icon unelevated we are approximating the relationship between points and their labels via circular functions.
A clustering algorithm approximates a model that determines clusters or unknown labels of input points
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
Maclaurin series
Taylor’s series
If you explore any of these extensions, I’d love to know. Post your findings in the comments below.
Further Reading
This section provides increasingly resources on the topic if you are looking to go deeper.
Tutorials
Resources
Books
Summary
In this tutorial, you discovered what is approximation. Specifically, you learned:
Approximation
Approximation when the form of a function is known
Approximation when the form of a function is unknown
Do you have any questions?
Ask your questions in the comments unelevated and I will do my weightier to answer