Develop a Neural Network for Woods Mammography Dataset
Tweet
Share
Share
It can be challenging to develop a neural network predictive model for a new dataset.
One tideway is to
7.2k
By Nick Cotes
It can be challenging to develop a neural network predictive model for a new dataset.
One tideway is to first inspect the dataset and develop ideas for what models might work, then explore the learning dynamics of simple models on the dataset, then finally develop and tune a model for the dataset with a robust test harness.
This process can be used to develop constructive neural network models for nomenclature and regression predictive modeling problems.
In this tutorial, you will discover how to develop a Multilayer Perceptron neural network model for the Wood’s Mammography nomenclature dataset.
After completing this tutorial, you will know:
How to load and summarize the Wood’s Mammography dataset and use the results to suggest data preparations and model configurations to use.
How to explore the learning dynamics of simple MLP models on the dataset.
How to develop robust estimates of model performance, tune model performance and make predictions on new data.
Let’s get started.
Develop a Neural Network for Woods Mammography Dataset Photo by Larry W. Lo, some rights reserved.
Tutorial Overview
This tutorial is divided into 4 parts; they are:
Woods Mammography Dataset
Neural Network Learning Dynamics
Robust Model Evaluation
Final Model and Make Predictions
Woods Mammography Dataset
The first step is to pinpoint and explore the dataset.
We will be working with the “mammography” standard binary nomenclature dataset, sometimes tabbed “Woods Mammography“.
The focus of the problem is on detecting breast cancer from radiological scans, specifically the presence of clusters of microcalcifications that towards unexceptionable on a mammogram.
There are two classes and the goal is to distinguish between microcalcifications and non-microcalcifications using the features for a given segmented object.
Non-microcalcifications: negative case, or majority class.
Microcalcifications: positive case, or minority class.
The Mammography dataset is a widely used standard machine learning dataset, used to explore and demonstrate many techniques planned specifically for imbalanced classification.
Note: To be crystal clear, we are NOT “solving breast cancer“. We are exploring a standard nomenclature dataset.
Below is a sample of the first 5 rows of the dataset
Running the example loads the dataset directly from the URL and reports the shape of the dataset.
In this case, we can personize that the dataset has 7 variables (6 input and one output) and that the dataset has 11,183 rows of data.
This a modest sized dataset for a neural network and suggests that a small network would be appropriate.
It moreover suggests that using k-fold cross-validation would be a good idea given that it will requite a increasingly reliable estimate of model performance than a train/test split and considering a each model will fit in seconds instead of hours or days with the largest datasets.
(11183, 7)
Next, we can learn increasingly well-nigh the dataset by looking at summary statistics and a plot of the data.
1
2
3
4
5
6
7
8
9
10
11
12
# show summary statistics and plots of the mammography dataset
max 3.150844e 01 5.085849e 00 ... 2.361712e 01 1.949027e 00
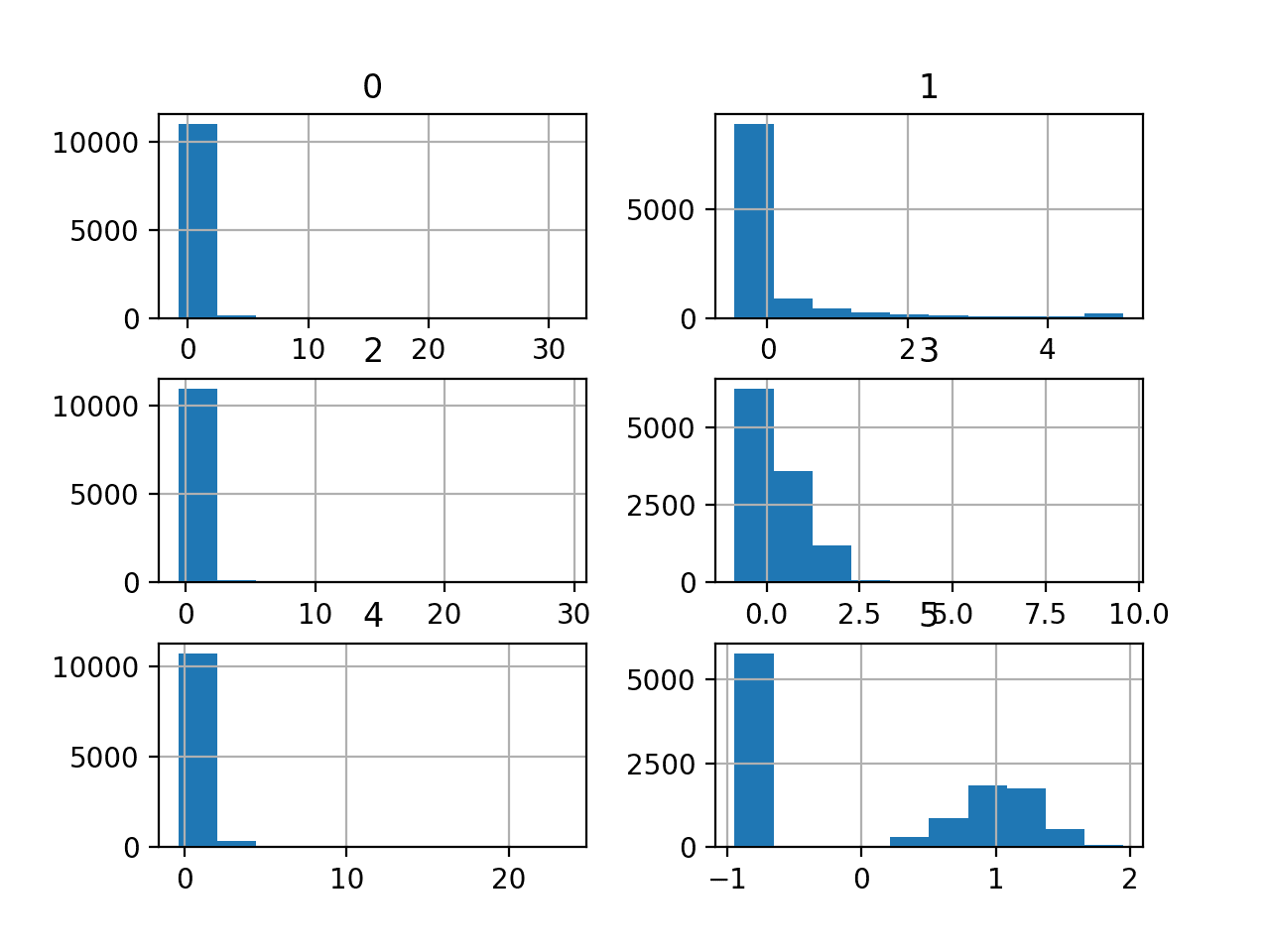
A histogram plot is then created for each variable.
We can see that perhaps most variables have an exponential distribution, and perhaps variable 5 (the last input variable) is Gaussian with outliers/missing values.
We may have some goody in using a power transform on each variable in order to make the probability distribution less skewed which will likely modernize model performance.
Histograms of the Mammography Nomenclature Dataset
It may be helpful to know how imbalanced the dataset unquestionably is.
We can use the Counter object to count the number of examples in each class, then use those counts to summarize the distribution.
The well-constructed example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
# summarize the matriculation ratio of the mammography dataset
Running the example summarizes the matriculation distribution, confirming the severe matriculation imbalanced with approximately 98 percent for the majority matriculation (no cancer) and approximately 2 percent for the minority matriculation (cancer).
Class='-1', Count=10923, Percentage=97.675%
Class='1', Count=260, Percentage=2.325%
This is helpful considering if we use nomenclature accuracy, then any model that achieves an verism less than well-nigh 97.7% does not have skill on this dataset.
Now that we are familiar with the dataset, let’s explore how we might develop a neural network model.
Neural Network Learning Dynamics
We will develop a Multilayer Perceptron (MLP) model for the dataset using TensorFlow.
We cannot know what model tracery of learning hyperparameters would be good or weightier for this dataset, so we must experiment and discover what works well.
Given that the dataset is small, a small batch size is probably a good idea, e.g. 16 or 32 rows. Using the Adam version of stochastic gradient descent is a good idea when getting started as it will automatically transmute the learning rate and works well on most datasets.
Before we evaluate models in earnest, it is a good idea to review the learning dynamics and tune the model tracery and learning configuration until we have stable learning dynamics, then squint at getting the most out of the model.
We can do this by using a simple train/test split of the data and review plots of the learning curves. This will help us see if we are over-learning or under-learning; then we can transmute the configuration accordingly.
First, we must ensure all input variables are floating-point values and encode the target label as integer values 0 and 1.
...
# ensure all data are floating point values
X=X.astype('float32')
# encode strings to integer
y=LabelEncoder().fit_transform(y)
Next, we can split the dataset into input and output variables, then into 67/33 train and test sets.
We must ensure that the split is stratified by the matriculation ensuring that the train and test sets have the same distribution of matriculation labels as the main dataset.
In this case, we will use one subconscious layer with 50 nodes and one output layer (chosen arbitrarily). We will use the ReLU vivification function in the subconscious layer and the “he_normal” weight initialization, as together, they are a good practice.
Running the example first fits the model on the training dataset, then reports the nomenclature verism on the test dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the stereotype outcome.
In this specimen we can see that the model performs largest than a no-skill model, given that the verism is whilom well-nigh 97.7 percent, in this specimen achieving an verism of well-nigh 98.8 percent.
Accuracy: 0.988
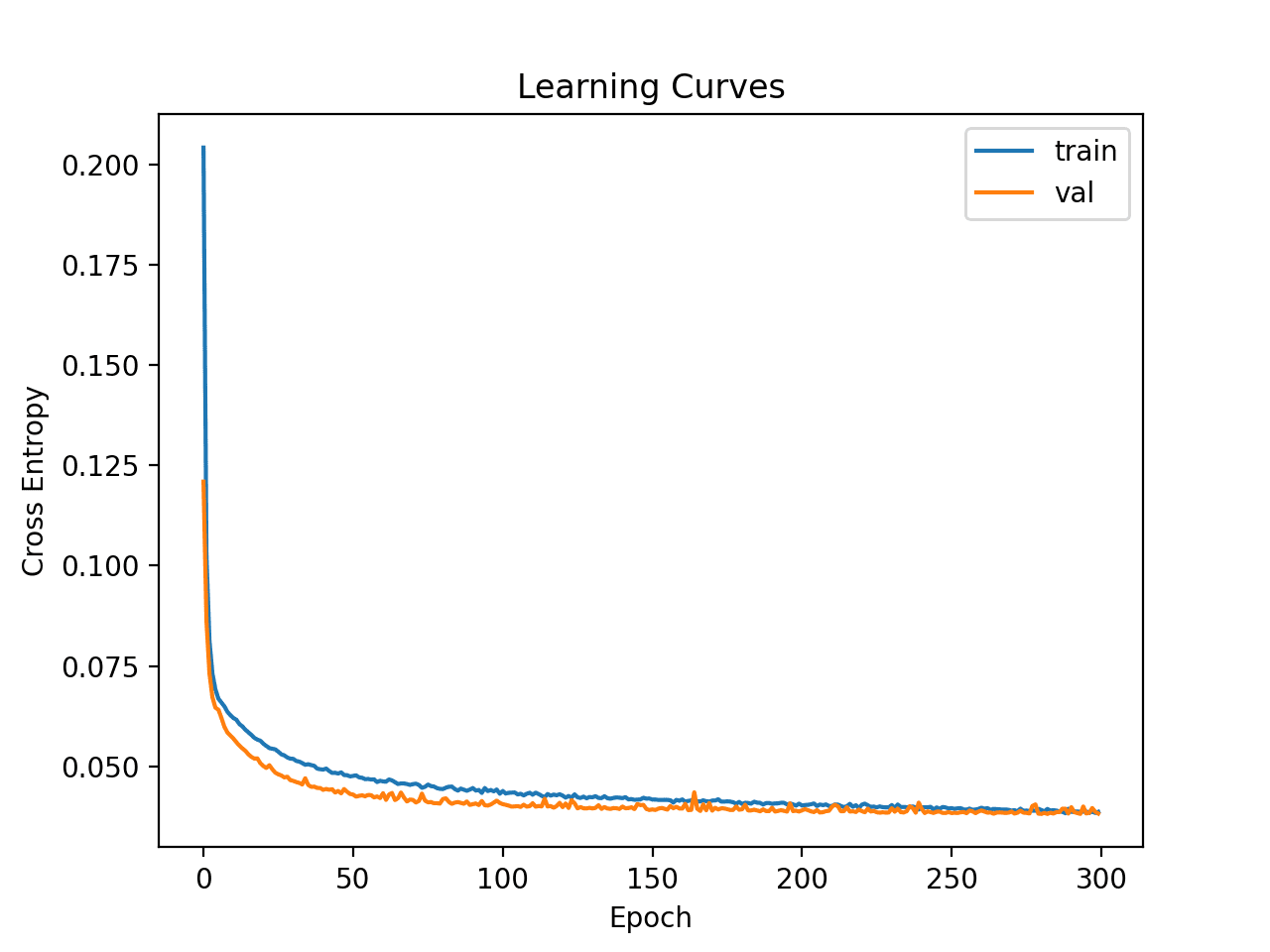
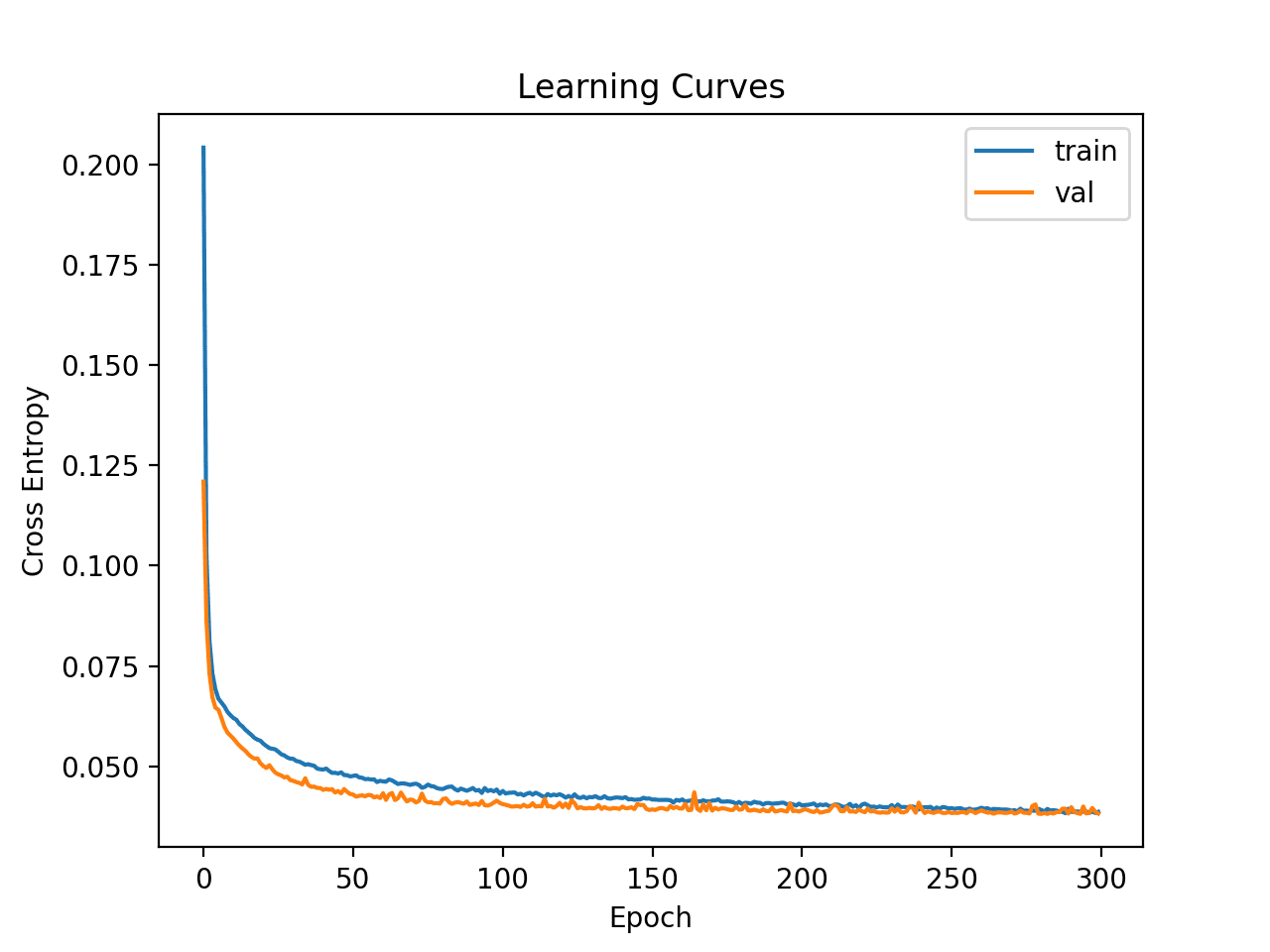
Line plots of the loss on the train and test sets are then created.
We can see that the model quickly finds a good fit on the dataset and does not towards to be over or underfitting.
Learning Curves of Simple Multilayer Perceptron on the Mammography Dataset
Now that we have some idea of the learning dynamics for a simple MLP model on the dataset, we can squint at developing a increasingly robust evaluation of model performance on the dataset.
Robust Model Evaluation
The k-fold cross-validation procedure can provide a increasingly reliable estimate of MLP performance, although it can be very slow.
This is considering k models must be fit and evaluated. This is not a problem when the dataset size is small, such as the cancer survival dataset.
We can use the StratifiedKFold matriculation and enumerate each fold manually, fit the model, evaluate it, and then report the midpoint of the evaluation scores at the end of the procedure.
We can use this framework to develop a reliable estimate of MLP model performance with our wiring configuration, and plane with a range of variegated data preparations, model architectures, and learning configurations.
It is important that we first ripened an understanding of the learning dynamics of the model on the dataset in the previous section surpassing using k-fold cross-validation to estimate the performance. If we started to tune the model directly, we might get good results, but if not, we might have no idea of why, e.g. that the model was over or under fitting.
If we make large changes to the model again, it is a good idea to go when and personize that the model is converging appropriately.
The well-constructed example of this framework to evaluate the wiring MLP model from the previous section is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# k-fold cross-validation of wiring model for the mammography dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.model_selection import StratifiedKFold
Running the example reports the model performance each iteration of the evaluation procedure and reports the midpoint and standard deviation of nomenclature verism at the end of the run.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the stereotype outcome.
In this case, we can see that the MLP model achieved a midpoint verism of well-nigh 98.7 percent, which is pretty tropical to our rough estimate in the previous section.
This confirms our expectation that the wiring model configuration may work largest than a naive model for this dataset
1
2
3
4
5
6
7
8
9
10
11
>0.987
>0.986
>0.989
>0.987
>0.986
>0.988
>0.989
>0.989
>0.983
>0.988
Mean Accuracy: 0.987 (0.002)
Next, let’s squint at how we might fit a final model and use it to make predictions.
Final Model and Make Predictions
Once we segregate a model configuration, we can train a final model on all misogynist data and use it to make predictions on new data.
In this case, we will use the model with dropout and a small batch size as our final model.
We can prepare the data and fit the model as before, although on the unshortened dataset instead of a training subset of the dataset.
Note: I took this row from the first row of the dataset and the expected label is a ‘-1’.
We can then make a prediction.
...
# make prediction
yhat=model.predict_classes([row])
Then capsize the transform on the prediction, so we can use or interpret the result in the correct label (which is just an integer for this dataset).
...
# capsize transform to get label for class
yhat=le.inverse_transform(yhat)
And in this case, we will simply report the prediction.
...
# report prediction
print('Predicted: %s'%(yhat[0]))
Tying this all together, the well-constructed example of fitting a final model for the mammography dataset and using it to make a prediction on new data is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# fit a final model and make predictions on new data for the mammography dataset
Running the example fits the model on the unshortened dataset and makes a prediction for a each row of new data.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the stereotype outcome.
In this case, we can see that the model predicted a “-1” label for the input row.
Predicted: '-1'
Further Reading
This section provides increasingly resources on the topic if you are looking to go deeper.
Tutorials
Summary
In this tutorial, you discovered how to develop a Multilayer Perceptron neural network model for the Wood’s Mammography nomenclature dataset.
Specifically, you learned:
How to load and summarize the Wood’s Mammography dataset and use the results to suggest data preparations and model configurations to use.
How to explore the learning dynamics of simple MLP models on the dataset.
How to develop robust estimates of model performance, tune model performance and make predictions on new data.
Do you have any questions? Ask your questions in the comments unelevated and I will do my weightier to answer.