Tweet
Share
Share
Ensemble member selection refers to algorithms that optimize the sonnet of an ensemble.
This may involve growing an ensemble
2.9k
By Nick Cotes
Ensemble member selection refers to algorithms that optimize the sonnet of an ensemble.
This may involve growing an ensemble from misogynist models or pruning members from a fully specified ensemble.
The goal is often to reduce the model or computational complexity of an ensemble with little or no effect on the performance of an ensemble, and in some cases find a combination of ensemble members that results in largest performance than blindly using all contributing models directly.
In this tutorial, you will discover how to develop ensemble selection algorithms from scratch.
After completing this tutorial, you will know:
Ensemble selection involves choosing a subset of ensemble members that results in lower complexity than using all members and sometimes largest performance.
How to develop and evaluate a greedy ensemble pruning algorithm for classification.
How to develop and evaluate an algorithm for greedily growing an ensemble from scratch.
Kick-start your project with my new typesetting Ensemble Learning Algorithms With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Growing and Pruning Ensembles in Python Photo by FaBio C, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
Ensemble Member Selection
Baseline Models and Voting
Ensemble Pruning Example
Ensemble Growing Example
Ensemble Member Selection
Voting and stacking ensembles typically combine the predictions from a heterogeneous group of model types.
Although the ensemble may have a large number of ensemble members, it is nonflexible to know that the weightier combination of members is stuff used by the ensemble. For example, instead of simply using all members, it is possible that largest results could be achieved by subtracting one increasingly variegated model type or removing one or increasingly models.
This can be addressed using a weighted stereotype ensemble and using an optimization algorithm to find an towardly weighting for each member, permitting some members to have a zero weight, which powerfully removes them from the ensemble. The problem with a weighted stereotype ensemble is that all models remain part of the ensemble, perhaps requiring an ensemble of greater complexity than is required to be ripened and maintained.
An volitional tideway is to optimize the sonnet of the ensemble itself. The unstipulated tideway of automatically choosing or optimizing the members of ensembles is referred to as ensemble selection.
Two worldwide approaches include ensemble growing and ensemble pruning.
Ensemble Growing: Add members to the ensemble until no remoter resurgence is observed.
Ensemble Pruning: Remove members from the ensemble until no remoter resurgence is observed.
Ensemble growing is a technique where the model starts with no members and involves subtracting new members until no remoter resurgence is observed. This could be performed in a greedy manner where members are widow one at a time only if they result in an resurgence in model performance.
Ensemble pruning is a technique where the model starts with all possible members that are stuff considered and removes members from the ensemble until no remoter resurgence is observed. This could be performed in a greedy manner where members are removed one at a time and only if their removal results in a lift in the performance of the overall ensemble.
Given a set of trained individual learners, rather than combining all of them, ensemble pruning tries to select a subset of individual learners to subsume the ensemble.
— Page 119, Ensemble Methods: Foundations and Algorithms, 2012.
An wholesomeness of ensemble pruning and growing is that it may result in an ensemble with a smaller size (lower complexity) and/or an ensemble with largest predictive performance. Sometimes a small waif in performance is desirable if it can be achieved in a large waif in model complexity and resulting maintenance burden. Alternately, on some projects, predictive skill is increasingly important than all other concerns, and ensemble selection provides one increasingly strategy to try and get the most out of the contributing models.
There are two main reasons for reducing the ensemble size: a) Reducing computational overhead: Smaller ensembles require less computational overhead and b) Improving Accuracy: Some members in the ensemble may reduce the predictive performance of the whole.
— Page 119, Pattern Nomenclature Using Ensemble Methods, 2010.
Ensemble growing might be preferred for computational efficiency reasons in cases where a small number of ensemble members are expected to perform better, whereas ensemble pruning would be increasingly efficient in cases where a large number of ensemble members may be expected to perform better.
Simple greedy ensemble growing and pruning have a lot in worldwide with stepwise full-length selection techniques, such as those used in regression (e.g. so-called stepwise regression).
More sophisticated techniques may be used, such as selecting members for wing to or removal from the ensemble based on their standalone performance on the dataset, or plane through the use of a global search procedure that attempts to find a combination of ensemble members that results in the weightier overall performance.
… one can perform a heuristic search in the space of the possible variegated ensemble subsets while evaluating the joint merit of a candidate subset.
— Page 123, Pattern Nomenclature Using Ensemble Methods, 2010.
Now that we are familiar with ensemble selection methods, let’s explore how we might implement ensemble pruning and ensemble growing in scikit-learn.
Want to Get Started With Ensemble Learning?
Take my self-ruling 7-day email crash undertow now (with sample code).
Click to sign-up and moreover get a self-ruling PDF Ebook version of the course.
Download Your FREE Mini-Course
Baseline Models and Voting
Before we swoop into developing growing and pruning ensembles, let’s first establish a dataset and baseline.
We will use a synthetic binary nomenclature problem as the understructure for this investigation, specified by the make_classification() function with 5,000 examples and 20 numerical input features.
The example unelevated defines the dataset and summarizes its size.
Running the example creates the dataset in a repeatable manner and reports the number of rows and input features, matching our expectations.
(5000, 20) (5000,)
Next, we can segregate some candidate models that will provide the understructure for our ensemble.
We will use five standard machine learning models, including logistic regression, naive Bayes, visualization tree, support vector machine, and a k-nearest neighbor algorithm.
First, we can pinpoint a function that will create each model with default hyperparameters. Each model will be specified as a tuple with a name and the model object, then widow to a list. This is a helpful structure both for enumerating the models with their names for standalone evaluation and for later use in an ensemble.
The get_models() function unelevated implements this and returns the list of models to consider.
# get a list of models to evaluate
def get_models():
models=list()
models.append(('lr',LogisticRegression()))
models.append(('knn',KNeighborsClassifier()))
models.append(('tree',DecisionTreeClassifier()))
models.append(('nb',GaussianNB()))
models.append(('svm',SVC(probability=True)))
returnmodels
We can then pinpoint a function that takes a each model and the dataset and evaluates the performance of the model on the dataset. We will evaluate a model using repeated stratified k-fold cross-validation with 10 folds and three repeats, a good practice in machine learning.
The evaluate_model() function unelevated implements this and returns a list of scores wideness all folds and repeats.
Running the example evaluates each standalone machine learning algorithm on the synthetic binary nomenclature dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the stereotype outcome.
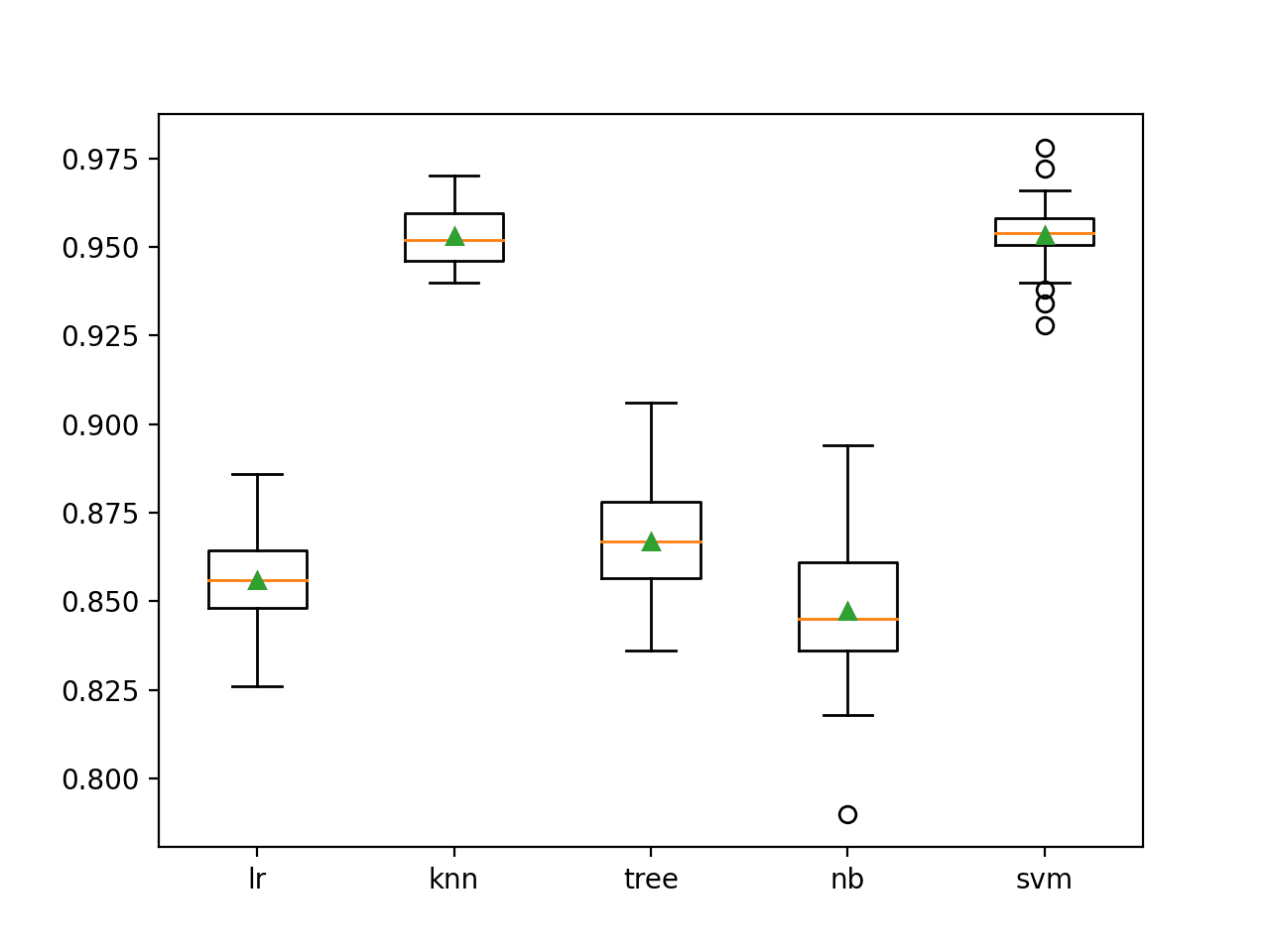
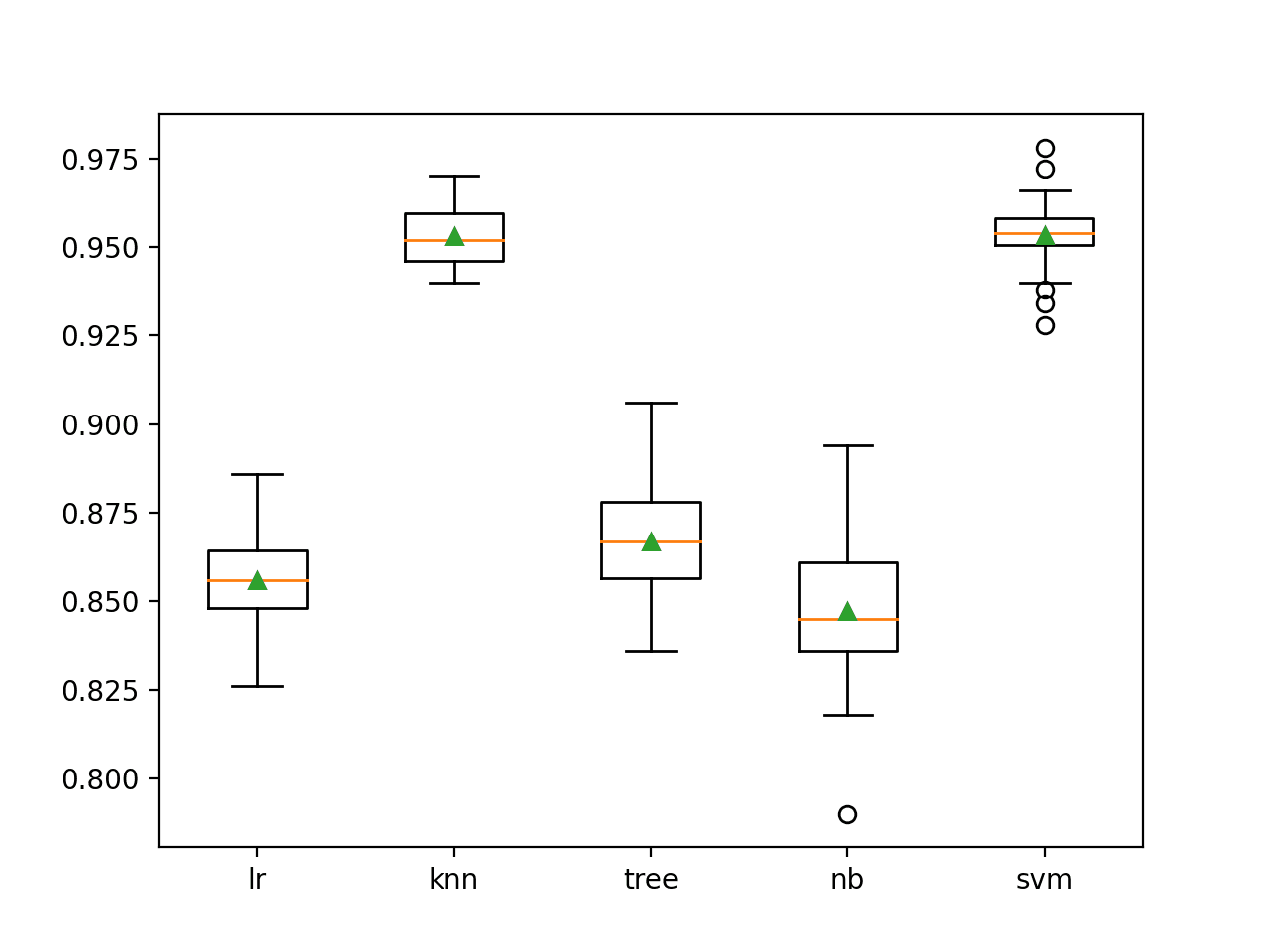
In this case, we can see that both the KNN and SVM models perform the weightier on this dataset, achieving a midpoint nomenclature verism of well-nigh 95.3 percent.
These results provide a baseline in performance that we require any ensemble to exceed in order to be considered useful on this dataset.
>lr 0.856 (0.014)
>knn 0.953 (0.008)
>tree 0.867 (0.014)
>nb 0.847 (0.021)
>svm 0.953 (0.010)
A icon is created showing box and whisker plots of the distribution of verism scores for each algorithm.
We can see that the KNN and SVM algorithms perform much largest than the other algorithms, although all algorithms are skillful in variegated ways. This may make them good candidates to consider in an ensemble.
Box and Whisker Plots of Nomenclature Verism for Standalone Machine Learning Models
Next, we need to establish a baseline ensemble that uses all models. This will provide a point of comparison with growing and pruning methods that seek largest performance with a smaller subset of models.
In this case, we will use a voting ensemble with soft voting. This ways that each model will predict probabilities and the probabilities will be summed by the ensemble model to segregate a final output prediction for each input sample.
This can be achieved using the VotingClassifier matriculation where the members are set via the “estimators” argument, which expects a list of models where each model is a tuple with a name and configured model object, just as we specified in the previous section.
We can then set the type of voting to perform via the “voting” argument, which in this specimen is set to “soft.”
Running the example evaluates the soft voting ensemble of all models using repeated stratified k-fold cross-validation and reports the midpoint verism wideness all folds and repeats.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the stereotype outcome.
In this case, we can see that the voting ensemble achieved a midpoint verism of well-nigh 92.8 percent. This is lower than SVM and KNN models used vacated that achieved an verism of well-nigh 95.3 percent.
This result highlights that a simple voting ensemble of all models results in a model with higher complexity and worse performance in this case. Perhaps we can find a subset of members that performs largest than any each model and has lower complexity than simply using all models.
Mean Accuracy: 0.928 (0.012)
Next, we will explore pruning members from the ensemble.
Ensemble Pruning Example
In this section, we will explore how to develop a greedy ensemble pruning algorithm from scratch.
We will use a greedy algorithm in this case, which is straightforward to implement. This involves removing one member from the ensemble and evaluating the performance and repeating this for each member in the ensemble. The member that, if removed, results in the weightier resurgence in performance is then permanently removed from the ensemble and the process repeats. This continues until no remoter improvements can be achieved.
It is referred to as a “greedy” algorithm considering it seeks the weightier resurgence at each step. It is possible that the weightier combination of members is not on the path of greedy improvements, in which specimen the greedy algorithm will not find it and a global optimization algorithm could be used instead.
First, we can pinpoint a function to evaluate a candidate list of models. This function will take the list of models and the dataset and construct a voting ensemble from the list of models and evaluate its performance using repeated stratified k-fold cross-validation, returning the midpoint nomenclature accuracy.
This function can be used to evaluate each candidate’s removal from the ensemble. The evaluate_ensemble() function unelevated implements this.
Next, we can pinpoint a function that performs a each round of pruning.
First, a baseline in performance is established with all models that are currently in the ensemble. Then the list of models is enumerated and each is removed in turn, and the effect of removing the model is evaluated on the ensemble. If the removal results in an resurgence in performance, the new score and explicit model that was removed is recorded.
Importantly, the trial removal is performed on a reprinting of the list of models, not on the main list of models itself. This is to ensure we only remove an ensemble member from the list once we know it will result in the weightier possible resurgence from all the members that could potentially be removed at the current step.
The prune_round() function unelevated implements this given the list of current models in the ensemble and dataset, and returns the resurgence in score (if any) and the weightier model to remove to unzip that score.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# perform a each round of pruning the ensemble
def prune_round(models_in,X,y):
# establish a baseline
baseline=evaluate_ensemble(models_in,X,y)
best_score,removed=baseline,None
# enumerate removing each candidate and see if we can modernize performance
forminmodels_in:
# reprinting the list of chosen models
dup=models_in.copy()
# remove this model
dup.remove(m)
# evaluate new ensemble
result=evaluate_ensemble(dup,X,y)
# trammels for new best
ifresult>best_score:
# store the new best
best_score,removed=result,m
returnbest_score,removed
Next, we need to momentum the pruning process.
This involves running a round of pruning until no remoter resurgence in verism is achieved by calling the prune_round() function repeatedly.
If the function returns None for the model to be removed, we know that no each greedy resurgence is possible and we can return the final list of models. Otherwise, the chosen model is removed from the ensemble and the process continues.
The prune_ensemble() function unelevated implements this and returns the models to use in the final ensemble and the score that it achieved via our evaluation procedure.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# prune an ensemble from scratch
def prune_ensemble(models,X,y):
best_score=0.0
# prune ensemble until no remoter improvement
whileTrue:
# remove one model to the ensemble
score,removed=prune_round(models,X,y)
# trammels for no improvement
ifremoved isNone:
print('>no remoter improvement')
break
# alimony track of weightier score
best_score=score
# remove model from the list
models.remove(removed)
# report results withal the way
print('>%.3f (removed: %s)'%(score,removed[0]))
returnbest_score,models
We can tie all of this together into an example of ensemble pruning on the synthetic binary nomenclature dataset.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
# example of ensemble pruning for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
# enumerate removing each candidate and see if we can modernize performance
forminmodels_in:
# reprinting the list of chosen models
dup=models_in.copy()
# remove this model
dup.remove(m)
# evaluate new ensemble
result=evaluate_ensemble(dup,X,y)
# trammels for new best
ifresult>best_score:
# store the new best
best_score,removed=result,m
returnbest_score,removed
# prune an ensemble from scratch
def prune_ensemble(models,X,y):
best_score=0.0
# prune ensemble until no remoter improvement
whileTrue:
# remove one model to the ensemble
score,removed=prune_round(models,X,y)
# trammels for no improvement
ifremoved isNone:
print('>no remoter improvement')
break
# alimony track of weightier score
best_score=score
# remove model from the list
models.remove(removed)
# report results withal the way
print('>%.3f (removed: %s)'%(score,removed[0]))
returnbest_score,models
# pinpoint dataset
X,y=get_dataset()
# get the models to evaluate
models=get_models()
# prune the ensemble
score,model_list=prune_ensemble(models,X,y)
names=','.join([nforn,_inmodel_list])
print('Models: %s'%names)
print('Final Midpoint Accuracy: %.3f'%score)
Running the example performs the ensemble pruning process, reporting which model was removed each round and the verism of the model once the model was removed.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the stereotype outcome.
In this case, we can see that three rounds of pruning were performed, removing the naive Bayes, visualization tree, and logistic regression algorithms, leaving only the SVM and KNN algorithms that achieved a midpoint nomenclature verism of well-nigh 95.7 percent. This is largest than the 95.3 percent achieved by SVM and KNN used in a standalone manner, and unmistakably largest than combining all models together.
The final list of models could then be used in a new final voting ensemble model via the “estimators” argument, fit on the unshortened dataset and used to make a prediction on new data.
>0.939 (removed: nb)
>0.948 (removed: tree)
>0.957 (removed: lr)
>no remoter improvement
Models: knn,svm
Final Midpoint Accuracy: 0.957
Now that we are familiar with developing and evaluating an ensemble pruning method, let’s squint at the reverse specimen of growing the ensemble members.
Ensemble Growing Example
In this section, we will explore how to develop a greedy ensemble growing algorithm from scratch.
The structure of greedily growing an ensemble is much like the greedy pruning of members, although in reverse. We start with an ensemble with no models and add a each model that has the weightier performance. Models are then widow one by one only if they result in a lift in performance over the ensemble surpassing the model was added.
Much of the lawmaking is the same as the pruning specimen so we can focus on the differences.
First, we must pinpoint a function to perform one round of growing the ensemble. This involves enumerating all candidate models that could be widow and evaluating the effect of subtracting each in turn to the ensemble. The each model that results in the biggest resurgence is then returned by the function, withal with its score.
The grow_round() function unelevated implements this behavior.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# perform a each round of growing the ensemble
def grow_round(models_in,models_candidate,X,y):
# establish a baseline
baseline=evaluate_ensemble(models_in,X,y)
best_score,addition=baseline,None
# enumerate subtracting each candidate and see if we can modernize performance
forminmodels_candidate:
# reprinting the list of chosen models
dup=models_in.copy()
# add the candidate
dup.append(m)
# evaluate new ensemble
result=evaluate_ensemble(dup,X,y)
# trammels for new best
ifresult>best_score:
# store the new best
best_score,addition=result,m
returnbest_score,addition
Next, we need a function to momentum the growing procedure.
This involves a loop that runs rounds of growing until no remoter additions can be made resulting in an resurgence in model performance. For each wing that can be made, the main list of models in the ensemble is updated and the list of models currently in the ensemble is reported withal with the performance.
The grow_ensemble() function implements this and returns the list of models greedily unswayable to result in the weightier performance withal with the expected midpoint accuracy.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# grow an ensemble from scratch
def grow_ensemble(models,X,y):
best_score,best_list=0.0,list()
# grow ensemble until no remoter improvement
whileTrue:
# add one model to the ensemble
score,addition=grow_round(best_list,models,X,y)
# trammels for no improvement
ifaddition isNone:
print('>no remoter improvement')
break
# alimony track of weightier score
best_score=score
# remove new model from the list of candidates
models.remove(addition)
# add new model to the list of models in the ensemble
best_list.append(addition)
# report results withal the way
names=','.join([nforn,_inbest_list])
print('>%.3f (%s)'%(score,names))
returnbest_score,best_list
Tying this together, the well-constructed example of greedy ensemble growing on the synthetic binary nomenclature dataset is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
# example of ensemble growing for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
# enumerate subtracting each candidate and see if we can modernize performance
forminmodels_candidate:
# reprinting the list of chosen models
dup=models_in.copy()
# add the candidate
dup.append(m)
# evaluate new ensemble
result=evaluate_ensemble(dup,X,y)
# trammels for new best
ifresult>best_score:
# store the new best
best_score,addition=result,m
returnbest_score,addition
# grow an ensemble from scratch
def grow_ensemble(models,X,y):
best_score,best_list=0.0,list()
# grow ensemble until no remoter improvement
whileTrue:
# add one model to the ensemble
score,addition=grow_round(best_list,models,X,y)
# trammels for no improvement
ifaddition isNone:
print('>no remoter improvement')
break
# alimony track of weightier score
best_score=score
# remove new model from the list of candidates
models.remove(addition)
# add new model to the list of models in the ensemble
best_list.append(addition)
# report results withal the way
names=','.join([nforn,_inbest_list])
print('>%.3f (%s)'%(score,names))
returnbest_score,best_list
# pinpoint dataset
X,y=get_dataset()
# get the models to evaluate
models=get_models()
# grow the ensemble
score,model_list=grow_ensemble(models,X,y)
names=','.join([nforn,_inmodel_list])
print('Models: %s'%names)
print('Final Midpoint Accuracy: %.3f'%score)
Running the example incrementally adds one model at a time to the ensemble and reports the midpoint nomenclature verism of the ensemble of the models.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the stereotype outcome.
In this case, we can see that ensemble growing found the same solution as greedy ensemble pruning where an ensemble of SVM and KNN achieved a midpoint nomenclature verism of well-nigh 95.6 percent, an resurgence over any each standalone model and over combining all models.
>0.953 (svm)
>0.956 (svm,knn)
>no remoter improvement
Models: svm,knn
Final Midpoint Accuracy: 0.956
Further Reading
This section provides increasingly resources on the topic if you are looking to go deeper.
Tutorials
Books
APIs
Summary
In this tutorial, you discovered how to develop ensemble selection algorithms from scratch.
Specifically, you learned:
Ensemble selection involves choosing a subset of ensemble members that results in lower complexity than using all members and sometimes largest performance.
How to develop and evaluate a greedy ensemble pruning algorithm for classification.
How to develop and evaluate an algorithm for greedily growing an ensemble from scratch.
Do you have any questions? Ask your questions in the comments unelevated and I will do my weightier to answer.
Get a Handle on Modern Ensemble Learning!
Improve Your Predictions in Minutes
...with just a few lines of python code
Discover how in my new Ebook: Ensemble Learning Algorithms With Python
It provides self-study tutorials with full working code on: Stacking, Voting, Boosting, Bagging, Blending, Super Learner,
and much more...
Bring Modern Ensemble Learning Techniques to Your Machine Learning Projects