Using Singular Value Decomposition to Build a Recommender System
Tweet
Share
Share
Last Updated on October 29, 2021
Singular value decomposition is a very popular linear algebra technique to break down
10.4k
By Nick Cotes
Last Updated on October 29, 2021
Singular value decomposition is a very popular linear algebra technique to break down a matrix into the product of a few smaller matrices. In fact, it is a technique that has many uses. One example is that we can use SVD to discover relationship between items. A recommender system can be build easily from this.
In this tutorial, we will see how a recommender system can be build just using linear algebra techniques.
After completing this tutorial, you will know:
What has singular value decomposition done to a matrix
How to interpret the result of singular value decomposition
What data a single recommender system require, and how we can make use of SVD to analyze it
How we can make use of the result from SVD to make recommendations
Let’s get started.
Using Singular Value Decomposition to Build a Recommender System Photo by Roberto Arias, some rights reserved.
Tutorial overview
This tutorial is divided into 3 parts; they are:
Review of Singular Value Decomposition
The Meaning of Singular Value Decomposition in Recommender System
Implementing a Recommender System
Review of Singular Value Decomposition
Just like a number such as 24 can be decomposed as factors 24=2×3×4, a matrix can also be expressed as multiplication of some other matrices. Because matrices are arrays of numbers, they have their own rules of multiplication. Consequently, they have different ways of factorization, or known as decomposition. QR decomposition or LU decomposition are common examples. Another example is singular value decomposition, which has no restriction to the shape or properties of the matrix to be decomposed.
Singular value decomposition assumes a matrix $M$ (for example, a $mtimes n$ matrix) is decomposed as $$ M = Ucdot Sigma cdot V^T $$ where $U$ is a $mtimes m$ matrix, $Sigma$ is a diagonal matrix of $mtimes n$, and $V^T$ is a $ntimes n$ matrix. The diagonal matrix $Sigma$ is an interesting one, which it can be non-square but only the entries on the diagonal could be non-zero. The matrices $U$ and $V^T$ are orthonormal matrices. Meaning the columns of $U$ or rows of $V$ are (1) orthogonal to each other and are (2) unit vectors. Vectors are orthogonal to each other if any two vectors’ dot product is zero. A vector is unit vector if its L2-norm is 1. Orthonormal matrix has the property that its transpose is its inverse. In other words, since $U$ is an orthonormal matrix, $U^T = U^{-1}$ or $Ucdot U^T=U^Tcdot U=I$, where $I$ is the identity matrix.
Singular value decomposition gets its name from the diagonal entries on $Sigma$, which are called the singular values of matrix $M$. They are in fact, the square root of the eigenvalues of matrix $Mcdot M^T$. Just like a number factorized into primes, the singular value decomposition of a matrix reveals a lot about the structure of that matrix.
But actually what described above is called the full SVD. There is another version called reduced SVD or compact SVD. We still have to write $M = UcdotSigmacdot V^T$ but we have $Sigma$ a $rtimes r$ square diagonal matrix with $r$ the rank of matrix $M$, which is usually less than or equal to the smaller of $m$ and $n$. The matrix $U$ is than a $mtimes r$ matrix and $V^T$ is a $rtimes n$ matrix. Because matrices $U$ and $V^T$ are non-square, they are called semi-orthonormal, meaning $U^Tcdot U=I$ and $V^Tcdot V=I$, with $I$ in both case a $rtimes r$ identity matrix.
The Meaning of Singular Value Decomposition in Recommender System
If the matrix $M$ is rank $r$, than we can prove that the matrices $Mcdot M^T$ and $M^Tcdot M$ are both rank $r$. In singular value decomposition (the reduced SVD), the columns of matrix $U$ are eigenvectors of $Mcdot M^T$ and the rows of matrix $V^T$ are eigenvectors of $M^Tcdot M$. What’s interesting is that $Mcdot M^T$ and $M^Tcdot M$ are potentially in different size (because matrix $M$ can be non-square shape), but they have the same set of eigenvalues, which are the square of values on the diagonal of $Sigma$.
This is why the result of singular value decomposition can reveal a lot about the matrix $M$.
Imagine we collected some book reviews such that books are columns and people are rows, and the entries are the ratings that a person gave to a book. In that case, $Mcdot M^T$ would be a table of person-to-person which the entries would mean the sum of the ratings one person gave match with another one. Similarly $M^Tcdot M$ would be a table of book-to-book which entries are the sum of the ratings received match with that received by another book. What can be the hidden connection between people and books? That could be the genre, or the author, or something of similar nature.
Implementing a Recommender System
Let’s see how we can make use of the result from SVD to build a recommender system. Firstly, let’s download the dataset from this link (caution: it is 600MB big)
This dataset is the “Social Recommendation Data” from “Recommender Systems and Personalization Datasets“. It contains the reviews given by users on books on Librarything. What we are interested are the number of “stars” a user given to a book.
If we open up this tar file we will see a large file named “reviews.json”. We can extract it, or read the included file on the fly. First three lines of reviews.json are shown below:
b"{'work': '3206242', 'flags': [], 'unixtime': 1194393600, 'stars': 5.0, 'nhelpful': 0, 'time': 'Nov 7, 2007', 'comment': 'This a great book for young readers to be introduced to the world of Middle Earth. ', 'user': 'van_stef'}n"
b"{'work': '12198649', 'flags': [], 'unixtime': 1333756800, 'stars': 5.0, 'nhelpful': 0, 'time': 'Apr 7, 2012', 'comment': 'Help Wanted: Tales of On The Job Terror from Evil Jester Press is a fun and scary read. This book is edited by Peter Giglio and has short stories by Joe McKinney, Gary Brandner, Henry Snider and many more. As if work wasnt already scary enough, this book gives you more reasons to be scared. Help Wanted is an excellent anthology that includes some great stories by some master storytellers.\nOne of the stories includes Agnes: A Love Story by David C. Hayes, which tells the tale of a lawyer named Jack who feels unappreciated at work and by his wife so he starts a relationship with a photocopier. They get along well until the photocopier starts wanting the lawyer to kill for it. The thing I liked about this story was how the author makes you feel sorry for Jack. His two co-workers are happily married and love their jobs while Jack is married to a paranoid alcoholic and he hates and works at a job he cant stand. You completely understand how he can fall in love with a copier because he is a lonely soul that no one understands except the copier of course.\nAnother story in Help Wanted is Work Life Balance by Jeff Strand. In this story a man works for a company that starts to let their employees do what they want at work. It starts with letting them come to work a little later than usual, then the employees are allowed to hug and kiss on the job. Things get really out of hand though when the company starts letting employees carry knives and stab each other, as long as it doesnt interfere with their job. This story is meant to be more funny then scary but still has its scary moments. Jeff Strand does a great job mixing humor and horror in this story.\nAnother good story in Help Wanted: On The Job Terror is The Chapel Of Unrest by Stephen Volk. This is a gothic horror story that takes place in the 1800s and has to deal with an undertaker who has the duty of capturing and embalming a ghoul who has been eating dead bodies in a graveyard. Stephen Volk through his use of imagery in describing the graveyard, the chapel and the clothes of the time, transports you into an 1800s gothic setting that reminded me of Bram Stokers Dracula.\nOne more story in this anthology that I have to mention is Expulsion by Eric Shapiro which tells the tale of a mad man going into a office to kill his fellow employees. This is a very short but very powerful story that gets you into the mind of a disgruntled employee but manages to end on a positive note. Though there were stories I didnt like in Help Wanted, all in all its a very good anthology. I highly recommend this book ', 'user': 'dwatson2'}n"
b"{'work': '12533765', 'flags': [], 'unixtime': 1352937600, 'nhelpful': 0, 'time': 'Nov 15, 2012', 'comment': 'Magoon, K. (2012). Fire in the streets. New York: Simon and Schuster/Aladdin. 336 pp. ISBN: 978-1-4424-2230-8. (Hardcover); $16.99.\nKekla Magoon is an author to watch (http://www.spicyreads.org/Author_Videos.html- scroll down). One of my favorite books from 2007 is Magoons The Rock and the River. At the time, I mentioned in reviews that we have very few books that even mention the Black Panther Party, let alone deal with them in a careful, thorough way. Fire in the Streets continues the story Magoon began in her debut book. While her familys financial fortunes drip away, not helped by her mothers drinking and assortment of boyfriends, the Panthers provide a very real respite for Maxie. Sam is still dealing with the death of his brother. Maxies relationship with Sam only serves to confuse and upset them both. Her friends, Emmalee and Patrice, are slowly drifting away. The Panther Party is the only thing that seems to make sense and she basks in its routine and consistency. She longs to become a full member of the Panthers and constantly battles with her Panther brother Raheem over her maturity and ability to do more than office tasks. Maxie wants to have her own gun. When Maxie discovers that there is someone working with the Panthers that is leaking information to the government about Panther activity, Maxie investigates. Someone is attempting to destroy the only place that offers her shelter. Maxie is determined to discover the identity of the traitor, thinking that this will prove her worth to the organization. However, the truth is not simple and it is filled with pain. Unfortunately we still do not have many teen books that deal substantially with the Democratic National Convention in Chicago, the Black Panther Party, and the social problems in Chicago that lead to the civil unrest. Thankfully, Fire in the Streets lives up to the standard Magoon set with The Rock and the River. Readers will feel like they have stepped back in time. Magoons factual tidbits add journalistic realism to the story and only improves the atmosphere. Maxie has spunk. Readers will empathize with her Atlas-task of trying to hold onto her world. Fire in the Streets belongs in all middle school and high school libraries. While readers are able to read this story independently of The Rock and the River, I strongly urge readers to read both and in order. Magoons recognition by the Coretta Scott King committee and the NAACP Image awards are NOT mistakes!', 'user': 'edspicer'}n"
b'{'work': '12981302', 'flags': [], 'unixtime': 1364515200, 'stars': 4.0, 'nhelpful': 0, 'time': 'Mar 29, 2013', 'comment': "Well, I definitely liked this book better than the last in the series. There was less fighting and more story. I liked both Toni and Ricky Lee and thought they were pretty good together. The banter between the two was sweet and often times funny. I enjoyed seeing some of the past characters and of course it's always nice to be introduced to new ones. I just wonder how many more of these books there will be. At least two hopefully, one each for Rory and Reece. ", 'user': 'amdrane2'}n'
Each line in reviews.json is a record. We are going to extract the “user”, “work”, and “stars” field of each record as long as there are no missing data among these three. Despite the name, the records are not well-formed JSON strings (most notably it uses single quote rather than double quote). Therefore, we cannot use json package from Python but to use ast to decode such string:
1
2
3
4
5
6
7
8
9
10
11
12
...
import ast
reviews=[]
with tarfile.open("lthing_data.tar.gz")astar:
with tar.extractfile("lthing_data/reviews.json")asfile:
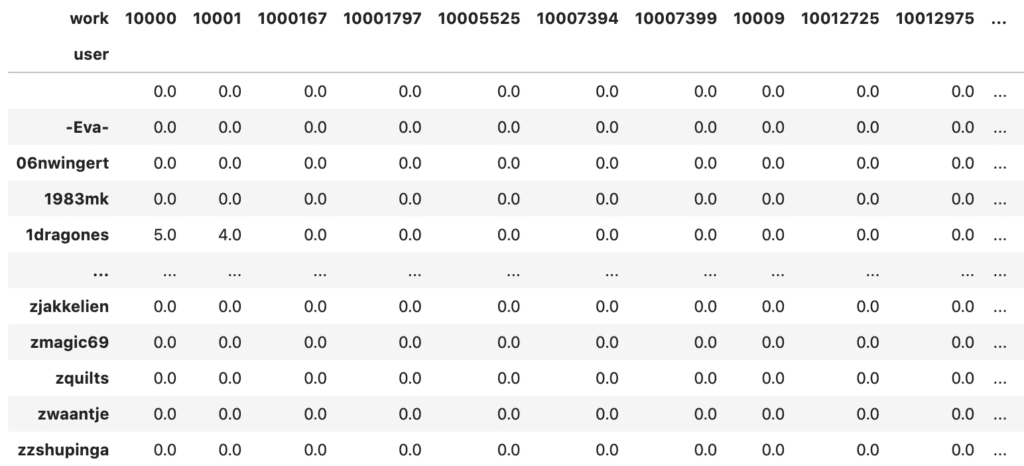
Now we should make a matrix of how different users rate each book. We make use of the pandas library to help convert the data we collected into a table:
As an example, we try not to use all data in order to save time and memory. Here we consider only those users who reviewed more than 50 books and also those books who are reviewed by more than 50 users. This way, we trimmed our dataset to less than 15% of its original size:
...
# Look for the users who reviewed more than 50 books
The result is a matrix of 5593 rows and 2898 columns
Here we represented 5593 users and 2898 books in a matrix. Then we apply the SVD (this will take a while):
...
from numpy.linalg import svd
matrix=reviewmatrix.values
u,s,vh=svd(matrix,full_matrices=False)
By default, the svd() returns a full singular value decomposition. We choose a reduced version so we can use smaller matrices to save memory. The columns of vh correspond to the books. We can based on vector space model to find which book are most similar to the one we are looking at:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
...
import numpy asnp
def cosine_similarity(v,u):
return(v@u)/(np.linalg.norm(v)*np.linalg.norm(u))
highest_similarity=-np.inf
highest_sim_col=-1
forcol inrange(1,vh.shape[1]):
similarity=cosine_similarity(vh[:,0],vh[:,col])
ifsimilarity>highest_similarity:
highest_similarity=similarity
highest_sim_col=col
print("Column %d is most similar to column 0"%highest_sim_col)
And in the above example, we try to find the book that is best match to to first column. The result is:
Column 906 is most similar to column 0
In a recommendation system, when a user picked a book, we may show her a few other books that are similar to the one she picked based on the cosine distance as calculated above.
Depends on the dataset, we may use truncated SVD to reduce the dimension of matrix vh. In essence, this means we are removing several rows on vh that the corresponding singular values in s are small, before we use it to compute the similarity. This would likely make the prediction more accurate as those less important features of a book are removed from consideration.
Note that, in the decomposition $M=UcdotSigmacdot V^T$ we know the rows of $U$ are the users and columns of $V^T$ are books, we cannot identify what are the meanings of the columns of $U$ or rows of $V^T$ (an equivalently, that of $Sigma$). We know they could be genres, for example, that provide some underlying connections between the users and the books but we cannot be sure what exactly are they. However, this does not stop us from using them as features in our recommendation system.
Tying all together, the following is the complete code: