A Gentle Introduction to Mixture of Experts Ensembles
Tweet
Share
Share
Mixture of experts is an ensemble learning technique ripened in the field of neural networks.
It involves decomposing predictive
7.6k
By Nick Cotes
Mixture of experts is an ensemble learning technique ripened in the field of neural networks.
It involves decomposing predictive modeling tasks into sub-tasks, training an expert model on each, developing a gating model that learns which expert to trust based on the input to be predicted, and combines the predictions.
Although the technique was initially described using neural network experts and gating models, it can be generalized to use models of any type. As such, it shows a strong similarity to stacked generalization and belongs to the matriculation of ensemble learning methods referred to as meta-learning.
In this tutorial, you will discover the mixture of experts tideway to ensemble learning.
After completing this tutorial, you will know:
An intuitive tideway to ensemble learning involves dividing a task into subtasks and developing an expert on each subtask.
Mixture of experts is an ensemble learning method that seeks to explicitly write a predictive modeling problem in terms of subtasks using expert models.
The divide and conquer tideway is related to the construction of visualization trees, and the meta-learner tideway is related to the stacked generalization ensemble method.
Kick-start your project with my new typesetting Ensemble Learning Algorithms With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
A Gentle Introduction to Mixture of Experts Ensembles Photo by Radek Kucharski, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
Subtasks and Experts
Mixture of Experts
Subtasks
Expert Models
Gating Model
Pooling Method
Relationship With Other Techniques
Mixture of Experts and Visualization Trees
Mixture of Experts and Stacking
Subtasks and Experts
Some predictive modeling tasks are remarkably complex, although they may be suited to a natural semester into subtasks.
For example, consider a one-dimensional function that has a ramified shape like an S in two dimensions. We could struggle to devise a model that models the function completely, but if we know the functional form, the S-shape, we could moreover divide up the problem into three parts: the lines at the top, the lines at the marrow and the line connecting the curves.
This is a divide and conquer tideway to problem-solving and underlies many streamlined approaches to predictive modeling, as well as problem-solving increasingly broadly.
This tideway can moreover be explored as the understructure for developing an ensemble learning method.
For example, we can divide the input full-length space into subspaces based on some domain knowledge of the problem. A model can then be trained on each subspace of the problem, stuff in effect an expert on the explicit subproblem. A model then learns which expert to undeniability upon to predict new examples in the future.
The subproblems may or may not overlap, and experts from similar or related subproblems may be worldly-wise to contribute to the examples that are technically outside of their expertise.
This tideway to ensemble learning underlies a technique referred to as a mixture of experts.
Mixture of Experts
Mixture of experts, MoE or ME for short, is an ensemble learning technique that implements the idea of training experts on subtasks of a predictive modeling problem.
In the neural network community, several researchers have examined the decomposition methodology. […] Mixture–of–Experts (ME) methodology that decomposes the input space, such that each expert examines a variegated part of the space. […] A gating network is responsible for combining the various experts.
— Page 73, Pattern Nomenclature Using Ensemble Methods, 2010.
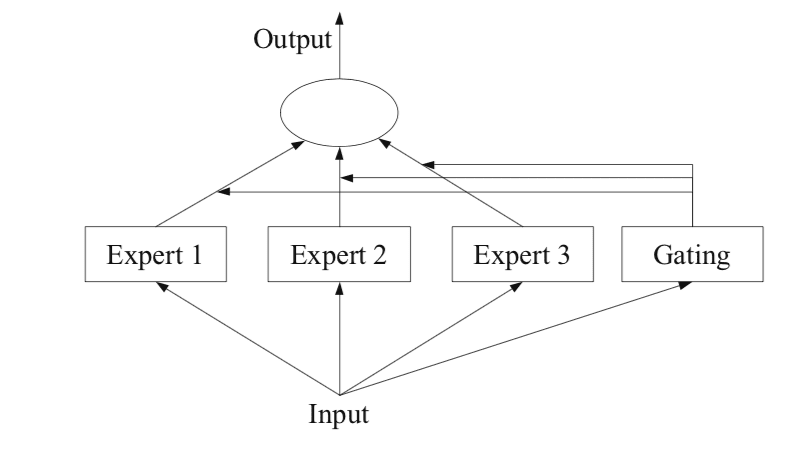
There are four elements to the approach, they are:
Division of a task into subtasks.
Develop an expert for each subtask.
Use a gating model to decide which expert to use.
Pool predictions and gating model output to make a prediction.
The icon below, taken from Page 94 of the 2012 typesetting “Ensemble Methods,” provides a helpful overview of the architectural elements of the method.
Example of a Mixture of Experts Model with Expert Members and a Gating Network Taken from: Ensemble Methods
Subtasks
The first step is to divide the predictive modeling problem into subtasks. This often involves using domain knowledge. For example, an image could be divided into separate elements such as background, foreground, objects, colors, lines, and so on.
… ME works in a divide-and-conquer strategy where a ramified task is wrenched up into several simpler and smaller subtasks, and individual learners (called experts) are trained for variegated subtasks.
— Page 94, Ensemble Methods, 2012.
For those problems where the semester of the task into subtasks is not obvious, a simpler and increasingly generic tideway could be used. For example, one could imagine an tideway that divides the input full-length space by groups of columns or separates examples in the full-length space based on loftiness measures, inliers, and outliers for a standard distribution, and much more.
… in ME, a key problem is how to find the natural semester of the task and then derive the overall solution from sub-solutions.
— Page 94, Ensemble Methods, 2012.
Expert Models
Next, an expert is planned for each subtask.
The mixture of experts tideway was initially ripened and explored within the field of strained neural networks, so traditionally, experts themselves are neural network models used to predict a numerical value in the specimen of regression or a matriculation label in the specimen of classification.
It should be well-spoken that we can “plug in” any model for the expert. For example, we can use neural networks to represent both the gating functions and the experts. The result is known as a mixture density network.
— Page 344, Machine Learning: A Probabilistic Perspective, 2012.
Experts each receive the same input pattern (row) and make a prediction.
Gating Model
A model is used to interpret the predictions made by each expert and to aid in deciding which expert to trust for a given input. This is tabbed the gating model, or the gating network, given that it is traditionally a neural network model.
The gating network takes as input the input pattern that was provided to the expert models and outputs the contribution that each expert should have in making a prediction for the input.
… the weights unswayable by the gating network are dynamically prescribed based on the given input, as the MoE powerfully learns which portion of the full-length space is learned by each ensemble member
— Page 16, Ensemble Machine Learning, 2012.
The gating network is key to the tideway and powerfully the model learns to segregate the type subtask for a given input and, in turn, the expert to trust to make a strong prediction.
Mixture-of-experts can moreover be seen as a classifier selection algorithm, where individual classifiers are trained to wilt experts in some portion of the full-length space.
— Page 16, Ensemble Machine Learning, 2012.
When neural network models are used, the gating network and the experts are trained together such that the gating network learns when to trust each expert to make a prediction. This training procedure was traditionally implemented using expectation maximization (EM). The gating network might have a softmax output that gives a probability-like conviction score for each expert.
In general, the training procedure tries to unzip two goals: for given experts, to find the optimal gating function; for a given gating function, to train the experts on the distribution specified by the gating function.
— Page 95, Ensemble Machine Learning, 2012.
Pooling Method
Finally, the mixture of expert models must make a prediction, and this is achieved using a pooling or team mechanism. This might be as simple as selecting the expert with the largest output or conviction provided by the gating network.
Alternatively, a weighted sum prediction could be made that explicitly combines the predictions made by each expert and the conviction unscientific by the gating network. You might imagine other approaches to making constructive use of the predictions and gating network output.
The pooling/combining system may then segregate a each classifier with the highest weight, or summate a weighted sum of the classifier outputs for each class, and pick the matriculation that receives the highest weighted sum.
— Page 16, Ensemble Machine Learning, 2012.
Want to Get Started With Ensemble Learning?
Take my self-ruling 7-day email crash undertow now (with sample code).
Click to sign-up and moreover get a self-ruling PDF Ebook version of the course.
Download Your FREE Mini-Course
Relationship With Other Techniques
The mixture of experts method is less popular today, perhaps considering it was described in the field of neural networks.
Nevertheless, increasingly than 25 years of advancements and exploration of the technique have occurred and you can see a unconfined summary in the 2012 paper “Twenty Years of Mixture of Experts.”
Importantly, I’d recommend considering the broader intent of the technique and explore how you might use it on your own predictive modeling problems.
For example:
Are there obvious or systematic ways that you can divide your predictive modeling problem into subtasks?
Are there specialized methods that you can train on each subtask?
Consider developing a model that predicts the conviction of each expert model.
Mixture of Experts and Visualization Trees
We can moreover see a relationship between a mixture of experts to Nomenclature And Regression Trees, often referred to as CART.
Decision trees are fit using a divide and conquer tideway to the full-length space. Each split is chosen as a unvarying value for an input full-length and each sub-tree can be considered a sub-model.
Mixture of experts was mostly studied in the neural networks community. In this thread, researchers often consider a divide-and-conquer strategy, try to learn a mixture of parametric models jointly and use combining rules to get an overall solution.
— Page 16, Ensemble Methods, 2012.
We could take a similar recursive decomposition tideway to decomposing the predictive modeling task into subproblems when designing the mixture of experts. This is often referred to as a hierarchical mixture of experts.
The hierarchical mixtures of experts (HME) procedure can be viewed as a variant of tree-based methods. The main difference is that the tree splits are not nonflexible decisions but rather soft probabilistic ones.
— Page 329, The Elements of Statistical Learning, 2016.
Unlike visualization trees, the semester of the task into subtasks is often explicit and top-down. Also, unlike a visualization tree, the mixture of experts attempts to survey all of the expert submodels rather than a each model.
There are other differences between HMEs and the CART implementation of trees. In an HME, a linear (or logistic regression) model is fit in each terminal node, instead of a unvarying as in CART. The splits can be multiway, not just binary, and the splits are probabilistic functions of a linear combination of inputs, rather than a each input as in the standard use of CART.
— Page 329, The Elements of Statistical Learning, 2016.
Nevertheless, these differences might inspire variations on the tideway for a given predictive modeling problem.
For example:
Consider will-less or unstipulated approaches to dividing the full-length space or problem into subtasks to help to broaden the suitability of the method.
Consider exploring both combination methods that trust the weightier expert, as well as methods that seek a weighted consensus wideness experts.
Mixture of Experts and Stacking
The using of the technique does not have to be limited to neural network models and a range of standard machine learning techniques can be used in place seeking a similar end.
In this way, the mixture of experts method belongs to a broader matriculation of ensemble learning methods that would moreover include stacked generalization, known as stacking. Like a mixture of experts, stacking trains a diverse ensemble of machine learning models and then learns a higher-order model to weightier combine the predictions.
We might refer to this matriculation of ensemble learning methods as meta-learning models. That is models that struggle to learn from the output or learn how to weightier combine the output of other lower-level models.
Meta-learning is a process of learning from learners (classifiers). […] In order to induce a meta classifier, first the wiring classifiers are trained (stage one), and then the Meta classifier (second stage).
— Page 82, Pattern Nomenclature Using Ensemble Methods, 2010.
Unlike a mixture of experts, stacking models are often all fit on the same training dataset, e.g. no decomposition of the task into subtasks. And moreover unlike a mixture of experts, the higher-level model that combines the predictions from the lower-level models typically does not receive the input pattern provided to the lower-level models and instead takes as input the predictions from each lower-level model.
Meta-learning methods are weightier suited for cases in which unrepealable classifiers unceasingly correctly classify, or unceasingly misclassify, unrepealable instances.
— Page 82, Pattern Nomenclature Using Ensemble Methods, 2010.
Nevertheless, there is no reason why hybrid stacking and mixture of expert models cannot be ripened that may perform largest than either tideway in isolation on a given predictive modeling problem.
For example:
Consider treating the lower-level models in stacking as experts trained on variegated perspectives of the training data. Perhaps this could involve using a softer tideway to decomposing the problem into subproblems where variegated data transforms or full-length selection methods are used for each model.
Consider providing the input pattern to the meta model in stacking in an effort to make the weighting or contribution of lower-level models provisionary on the explicit context of the prediction.
Further Reading
This section provides increasingly resources on the topic if you are looking to go deeper.
Papers
Books
Articles
Summary
In this tutorial, you discovered mixture of experts tideway to ensemble learning.
Specifically, you learned:
An intuitive tideway to ensemble learning involves dividing a task into subtasks and developing an expert on each subtask.
Mixture of experts is an ensemble learning method that seeks to explicitly write a predictive modeling problem in terms of subtasks using expert models.
The divide and conquer tideway is related to the construction of visualization trees, and the meta-learner tideway is related to the stacked generalization ensemble method.
Do you have any questions? Ask your questions in the comments unelevated and I will do my weightier to answer.
Get a Handle on Modern Ensemble Learning!
Improve Your Predictions in Minutes
...with just a few lines of python code
Discover how in my new Ebook: Ensemble Learning Algorithms With Python
It provides self-study tutorials with full working code on: Stacking, Voting, Boosting, Bagging, Blending, Super Learner,
and much more...
Bring Modern Ensemble Learning Techniques to Your Machine Learning Projects