Tweet
Share
Share
We have already familiarized ourselves with the concept of self-attention as implemented by the Transformer attention mechanism for
5.2k
By Nick Cotes
We have already familiarized ourselves with the concept of self-attention as implemented by the Transformer attention mechanism for neural machine translation. We will now be shifting our focus on the details of the Transformer architecture itself, to discover how self-attention can be implemented without relying on the use of recurrence and convolutions.
In this tutorial, you will discover the network architecture of the Transformer model.
After completing this tutorial, you will know:
How the Transformer architecture implements an encoder-decoder structure without recurrence and convolutions.
How the Transformer encoder and decoder work.
How the Transformer self-attention compares to the use of recurrent and convolutional layers.
Let’s get started.
The Transformer Model Photo by Samule Sun, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
The Transformer Architecture
The Encoder
The Decoder
Sum Up: The Transformer Model
Comparison to Recurrent and Convolutional Layers
Prerequisites
For this tutorial, we assume that you are already familiar with:
The Transformer Architecture
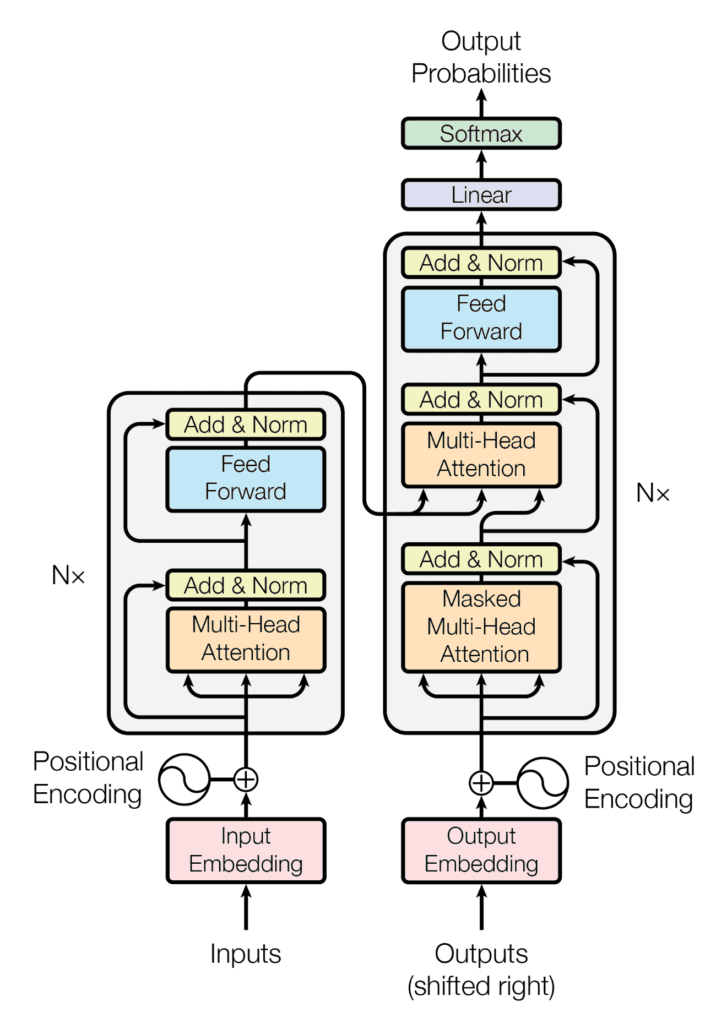
The Transformer architecture follows an encoder-decoder structure, but does not rely on recurrence and convolutions in order to generate an output.
The Encoder-Decoder Structure of the Transformer Architecture Taken from “Attention Is All You Need“
In a nutshell, the task of the encoder, on the left half of the Transformer architecture, is to map an input sequence to a sequence of continuous representations, which is then fed into a decoder.
The decoder, on the right half of the architecture, receives the output of the encoder together with the decoder output at the previous time step, to generate an output sequence.
At each step the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next.
– Attention Is All You Need, 2017.
The Encoder
The Encoder Block of the Transformer Architecture Taken from “Attention Is All You Need“
The encoder consists of a stack of $N$ = 6 identical layers, where each layer is composed of two sublayers:
The first sublayer implements a multi-head self-attention mechanism. We had seen that the multi-head mechanism implements $h$ heads that receive a (different) linearly projected version of the queries, keys and values each, to produce $h$ outputs in parallel that are then used to generate a final result.
The second sublayer is a fully connected feed-forward network, consisting of two linear transformations with Rectified Linear Unit (ReLU) activation in between:
$$text{FFN}(x) = text{ReLU}(mathbf{W}_1 x + b_1) mathbf{W}_2 + b_2$$
The six layers of the Transformer encoder apply the same linear transformations to all of the words in the input sequence, but each layer employs different weight ($mathbf{W}_1, mathbf{W}_2$) and bias ($b_1, b_2$) parameters to do so.
Furthermore, each of these two sublayers has a residual connection around it.
Each sublayer is also succeeded by a normalization layer, $text{layernorm}(.)$, which normalizes the sum computed between the sublayer input, $x$, and the output generated by the sublayer itself, $text{sublayer}(x)$:
$$text{layernorm}(x + text{sublayer}(x))$$
An important consideration to keep in mind is that the Transformer architecture cannot inherently capture any information about the relative positions of the words in the sequence, since it does not make use of recurrence. This information has to be injected by introducing positional encodings to the input embeddings.
The positional encoding vectors are of the same dimension as the input embeddings, and are generated using sine and cosine functions of different frequencies. Then, they are simply summed to the input embeddings in order to inject the positional information.
The Decoder
The Decoder Block of the Transformer Architecture Taken from “Attention Is All You Need“
The decoder shares several similarities with the encoder.
The decoder also consists of a stack of $N$ = 6 identical layers that are, each, composed of three sublayers:
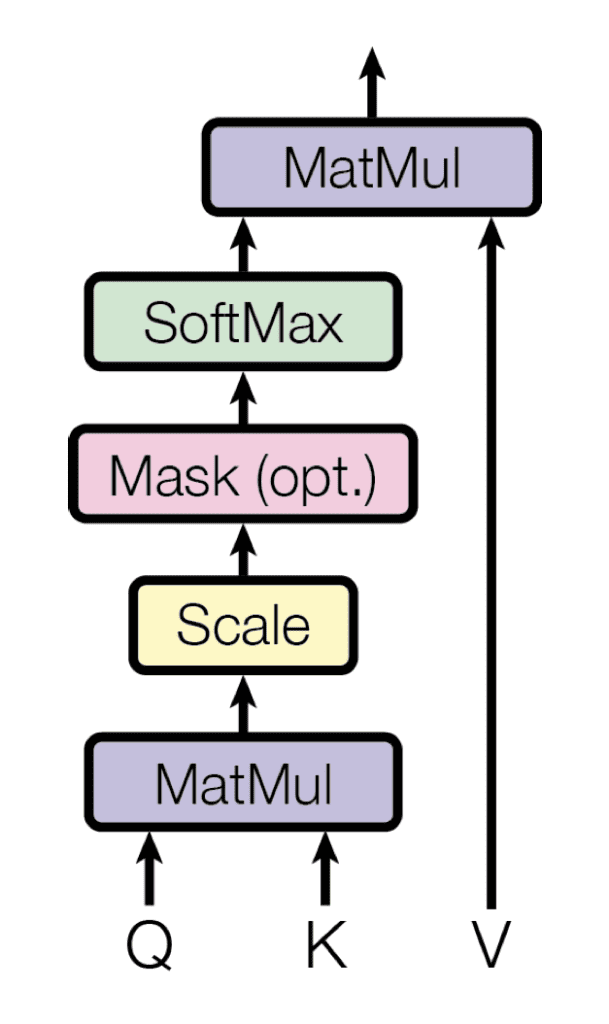
The first sublayer receives the previous output of the decoder stack, augments it with positional information, and implements multi-head self-attention over it. While the encoder is designed to attend to all words in the input sequence, regardless of their position in the sequence, the decoder is modified to attend only to the preceding words. Hence, the prediction for a word at position, $i$, can only depend on the known outputs for the words that come before it in the sequence.In the multi-head attention mechanism (which implements multiple, single attention functions in parallel), this is achieved by introducing a mask over the values produced by the scaled multiplication of matrices $mathbf{Q}$ and $mathbf{K}$. This masking is implemented by suppressing the matrix values that would, otherwise, correspond to illegal connections:
The Multi-Head Attention in the Decoder Implements Several Masked, Single Attention Functions Taken from “Attention Is All You Need“
The masking makes the decoder unidirectional (unlike the bidirectional encoder).
–Advanced Deep Learning with Python, 2019.
The second layer implements a multi-head self-attention mechanism, which is similar to the one implemented in the first sublayer of the encoder.On the decoder side, this multi-head mechanism receives the queries from the previous decoder sublayer, and the keys and values from the output of the encoder. This allows the decoder to attend to all of the words in the input sequence.
The third layer implements a fully connected feed-forward network, which is similar to the one implemented in the second sublayer of the encoder.
Furthermore, the three sublayers on the decoder side also have residual connections around them, and are succeeded by a normalization layer.
Positional encodings are also added to the input embeddings of the decoder, in the same manner as previously explained for the encoder.
Sum Up: The Transformer Model
The Transformer model runs as follows:
Each word forming an input sequence is transformed into a $d_{text{model}}$-dimensional embedding vector.
Each embedding vector representing an input word is augmented by summing it (element-wise) to a positional encoding vector of the same $d_{text{model}}$ length, hence introducing positional information into the input.
The augmented embedding vectors are fed into the encoder block, consisting of the two sublayers explained above. Since the encoder attends to all words in the input sequence, irrespective if they precede or succeed the word under consideration, then the Transformer encoder is bidirectional.
The decoder receives as input its own predicted output word at time-step, $t – 1$.
The input to the decoder is also augmented by positional encoding, in the same manner as this is done on the encoder side.
The augmented decoder input is fed into the three sublayers comprising the decoder block explained above. Masking is applied in the first sublayer, in order to stop the decoder from attending to succeeding words. At the second sublayer, the decoder also receives the output of the encoder, which now allows the decoder to attend to all of the words in the input sequence.
The output of the decoder finally passes through a fully connected layer, followed by a softmax layer, to generate a prediction for the next word of the output sequence.
Comparison to Recurrent and Convolutional Layers
Vaswani et al. (2017) explain that their motivation for abandoning the use of recurrence and convolutions was based on several factors:
Self-attention layers were found to be faster than recurrent layers for shorter sequence lengths, and can be restricted to consider only a neighbourhood in the input sequence for very long sequence lengths.
The number of sequential operations required by a recurrent layer is based upon the sequence length, whereas this number remains constant for a self-attention layer.
In convolutional neural networks, the kernel width directly affects the long-term dependencies that can be established between pairs of input and output positions. Tracking long-term dependencies would require the use of large kernels, or stacks of convolutional layers that could increase the computational cost.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
Papers
Summary
In this tutorial, you discovered the network architecture of the Transformer model.
Specifically, you learned:
How the Transformer architecture implements an encoder-decoder structure without recurrence and convolutions.
How the Transformer encoder and decoder work.
How the Transformer self-attention compares to recurrent and convolutional layers.
Do you have any questions? Ask your questions in the comments below and I will do my best to answer.