Tweet
Tweet
Share
Share
Last Updated on April 23, 2022
In the old days, it was a tedious job to collect data,
6.8k
By Nick Cotes
Last Updated on April 23, 2022
In the old days, it was a tedious job to collect data, and sometimes very expensive. Machine learning projects cannot live without data. Luckily, we have a lot of data on the web for our disposal nowadays. We can copy data from the web to create our dataset. We can download files and save to the disk. But we can do it more efficiently by automating the data harvesting. There are several tools in Python that can help the automation.
After finishing this tutorial, you will learn
How to use requests library to read online data using HTTP
How to read tables on web pages using pandas
How to use Selenium to emulate browser operations
Let’s get started!
Web Crawling in Python Photo by Ray Bilcliff. Some rights reserved.
Overview
This tutorial is divided into three parts:
Using the requests library
Reading tables on the web using pandas
Reading dynamic content with Selenium
Using the requests library
When we talk about writing a Python program to read from the web, it is inevitable to avoid the requests library. You need to install it (as well as BeautifulSoup and lxml that we will cover later):
pip install requests beautifulsoup4 lxml
and it provides you an interface to allow you to interact with the web easily.
The very simple use case would be to read a web page from a URL:
If you’re familiar with HTTP, probably you can recall that a status code of 200 means the request is successfully fulfilled. Then we can read the response. In above, we read the textual response and get the HTML of the web page. Should it be a CSV or some other textual data, we can get them in the text attribute of the response object. For example, this is how we can read a CSV from the Federal Reserve Economics Data:
If the data is in the form of JSON, we can read it as text or even let requests to decode it for you. For example, the following is to pull some data from GitHub in JSON format and convert it into Python dictionary:
But if the URL gives you some binary data, such as a ZIP file or an JPEG image, you need to get them in the content attribute instead as this would be the binary data. For example, this is how we can download an image (the logo of Wikipedia):
Given we already obtained the web page, how should we extract the data? This is beyond the requests library can provide to us but we can use a different library to help. There are two ways we can do it, depends on how do we want to specify the data.
First way is to consider the HTML as a kind of XML document and use the XPath language to extract the element. In this case, we can make use of the lxml library to first create a document object model (DOM) and then search by XPath:
...
from lxml import etree
# Create DOM from HTML text
dom=etree.HTML(resp.text)
# Search for the temperature element and get the content
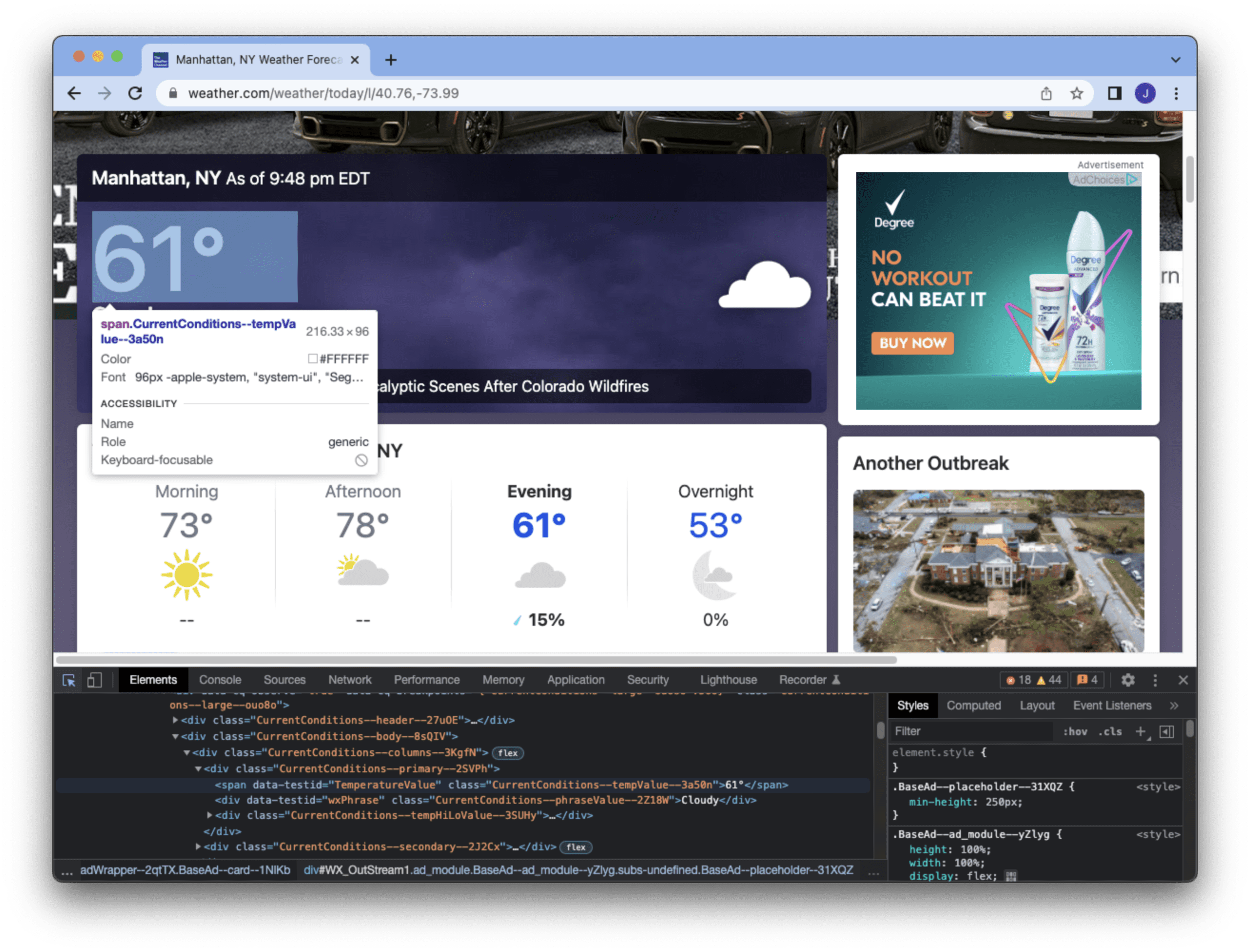
elements=dom.xpath("//span[@data-testid='TemperatureValue' and contains(@class,'CurrentConditions')]")
print(elements[0].text)
XPath is a string that specifies on how to find an element. The lxml object provides a function xpath() to search the DOM for elements that match the XPath string, which can be multiple matches. The XPath above means to find a HTML element anywhere with the <span> tag and with the attribute data-testid matches “TemperatureValue” and class begins with “CurrentConditions“. We can learn this from the developer tools of the browser (e.g., the Chrome screenshot below), by inspecting the HTML source.
This example is to find the temperature of New York City, provided by this particular element we get from this web page. We know the first element matched by the XPath is what we need and we can read the text inside the <span> tag.
The other way is to use CSS selectors on the HTML document, which we can make use of the BeautifulSoup library:
In above, we first pass our HTML text to BeautifulSoup. BeautifulSoup supports various HTML parsers, each with different capabilities. In the above, we use the lxml library as the parser as recommended by BeautifulSoup (and it is also often the fastest). CSS selector is a different mini-language, which has pros and cons compared to XPath. The selector above is identical to the XPath we used in the previous example. Therefore, we can get the same temperature from the first matched element.
The following is a complete code to print the current temperature of New York according to the real-time information on the web:
As you can imagine, you can collect a time series of the temperature by running this script in regular schedule. Similarly, we can collect data automatically from various web sites. This is how we can obtain data for our machine learning projects.
Reading tables on the web using pandas
Very often, web pages will use tables to carry data. If the page is simple enough, we may even skip inspecting it to find out the XPath or CSS selector but to use pandas to get all tables on the page in one shot. It is simple enough to be done in one line:
The read_html() function in pandas reads a URL and find all tables on the page. Each table is converted into a pandas DataFrame, and then return all of them in a list. In this example, we are reading the various interest rates from the Federal Reserve, which happens to have only one table on this page. The table columns are identified by pandas automatically.
Chances are that not all tables are what we are interested. Sometimes the web page will use table merely as a way to format the page but pandas maybe not smart enough to tell. Hence we need to test and cherry-pick the result returned by the read_html() function.
Reading dynamic content with Selenium
A significant portion of modern day web pages are full of JavaScripts. This gives us fancier experience but becomes a hurdle to use a program to extract data. One example is Yahoo’s home page, which if we just load the page and find all news headline, there are far fewer than what we can see on the browser:
This is because web pages like this rely on JavaScript to populate the content. Famous web frameworks such as AngularJS or React are behind powering this category. The Python library such as requests does not understand JavaScript. Therefore you will see the result differently. If the data you want to fetch from the web are one of them, you can study how the JavaScript is invoked and mimic the browser’s behavior in your program. But this probably too tedious to make it work.
The other way is to ask a real browser to read the web page rather than using requests. This is where Selenium can do. Before we can use it, we need to install the library:
pip install selenium
But Selenium is only a framework to control browsers. You need to have the browser installed on your computer as well as the driver to connect Selenium to the browser. If you intended to use Chrome, you need to download and install ChromeDriver too. What you need to do is simply put the driver in the executable path so Selenium can invoke it like a normal command. For example, in Linux, you just need to get the chromedriver executable from the ZIP file downloaded and put it in /usr/local/bin.
Similarly, if you’re using Firefox, you need the GeckoDriver. For more details on setting up Selenium, you should refer to its documentation.
Afterwards, you can using Python script to control the browser behavior. For example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
# Launch Chrome browser in headless mode
options=webdriver.ChromeOptions()
options.add_argument("headless")
browser=webdriver.Chrome(options=options)
# Load web page
browser.get("https://www.yahoo.com")
# Network transport takes time. Wait until the page is fully loaded
def is_ready(browser):
returnbrowser.execute_script(r"""
return document.readyState === 'complete'
""")
WebDriverWait(browser,30).until(is_ready)
# Scroll to bottom of the page to trigger JavaScript action
The above code works as follows. We first launch the browser in headless mode, meaning to ask Chrome to start but not display on the screen. This is important if we want to run our script remotely as there may not be any GUI suppport. Note that every browser is developed differently and thus the options syntax we used is specific to Chrome. If we use Firefox, the code should be this instead:
After we launched the browser, we give it a URL to load. But since it takes time for the network to deliver the page and the browser would take time to render it, we should wait until the browser is ready before we proceed to next operation. The way we detect if the browser has finished rendering is by using JavaScript. We make Selenium to run a JavaScript code for us and tell us the result using the execute_script() function. We leverage Selenium’s WebDriverWait tool to run it until it succeed, or until 30 second timeout. As the page is loaded, we scroll to the bottom of the page so the JavaScript can be triggered to load more content. Then we wait for one second unconditionally to make sure the browser triggered the JavaScript, then wait until the page is ready again. Afterwards, we can extract the news headline element using XPath (or alternatively using CSS selector). Because the browser is an external program, we are responsible to close it in our script.
Using Selenium is different from using requests library in several aspects. First you never have the web content in your Python code directly. Instead, you are referring to the content in the browser whenever you need it. Hence the web elements returned by find_elements() function are referring to objects inside the external browser, which we must not close the browser before we finish consuming them. Secondly, all operation should be based on browser interaction, rather than network requests. Thus you need to control the browser by emulating keyboard and mouse movements. But in return, you have the full-featured browser with JavaScript support. For example, you can use JavaScript to check the size and position of an element on the page, which you will know only after the HTML elements are rendered.
There are a lot more functions provided by the Selenium framework that we can cover here. It is powerful but since it is connected to the browser, using it is more demanding than the requests library and much slower. Usually this is the last resort for harvesting information from the web.
Further Reading
Another famous web crawling library in Python that we didn’t covered above is Scrapy. It is like combining requests library with BeautifulSoup into one. The web protocol is complex. Sometimes we need to manage web cookies or provide extra data to the requests using POST method. All these can be done with requests library with a different function or extra arguments. The following are some resources for you to go deeper:
Articles
API documentations
Books
Summary
In this tutorial, you saw the tools we can use to fetch content from the web.
Specifically, you learned:
How to use the requests library to send the HTTP request and extract data from its response
How to build a document object model from HTML so we can find some specific information on a web page
How to read tables on a web page quick and easily using pandas
How to use Selenium to control a browser to tackle dynamic content of a web page